교과목 개요
석,박사 과정
WST500 웹사이언스 공학개론
웹은 온라인에서 만나는 사람들 간의 의사소통, 신뢰, 자기 정체성, 집단 지능의 구현의 플랫폼의 역할 뿐만 아니라 미디어로서 사회 정치적 의견, 그룹 의사결정, 온라인 평판 생성을 가능하게 하는 미디어로써의 역할을 한다. 본 과목에서는 이러한 웹의 역할과 기능을 인문사회학, 법학, 자연과학, 공학 등 다양한 학문이 융합된 새로운 차원에서 다루는 웹 사이언스 공학을 개관한다.
WST501 웹 스케일 자료 검색 기초 이론
이 과목에서는 Large Dataset상의 queries를 서포트하기 위하여 실제 흔히 적용되는 인덱스 구조와 알고리즘을 공부한다. 이 과목은 각각 data streams, multi-dimensional objects, 그리고 web-specific applications에 초점을 맞춘 세 부분으로 나누어져 다음의 주제를 포함한다: sampling, hashing, sketch structures,R-trees, nearest neighbor search, instance optimality. 또한 알고리즘의 성능을 분석하기 위한 기본 테크닉을 배운다.
WST510 웹 아키텍쳐
웹 서비스 구축 및 웹 아키텍처에 대하여 강의한다. 웹 아키텍쳐의 설계 원리를 다루고 성능과 안정성 이슈에 대하여 다룬다.
WST520 웹소프트웨어 공학
웹의 역할과 제공하는 기능이 진화, 발전함에 따라 웹 기반의 시스템을 개발하기 위한 소프트웨어 공학의 역할과 웹의 자원을 이용하여 엔지니어링 작업을 수행하는 소프트웨어 엔지니어 능력의 중요성도 함께 부각 되게 되었다. 이러한 추세는 전문 소프트웨어 엔지니어에 의해 수행되는 소프트웨어 공학적 개발 과정에 영향을 미치게 되었을 뿐만 아니라 최종 사용자 프로그래밍을 가능하게 하는 웹 기반 플랫폼의 등장을 초래하게 되었다. 이 과목에서는 이렇게 웹의 발전이 소프트웨어 공학에 미친 영향에 대해 살펴보고, ‘최종 사용자를 위한 소프트웨어 공학(End-user Software Engineering)’과 관련된 제반 현상과 의미, 연구 방향에 대해 학습한다.
WST540 웹 검색 및 텍스트 분석
웹검색엔진의 모델링과 알고리즘을 공부한다. 핵심토픽에는 tf-idf 계산법, 페이지순위화, 역색인, trie, 접미사 트리, 문자열 B-트리, q-그램, 오류극복형 키워드검색, deep웹 등이 있다. 이 과목에 텍스트검색과 링크분석의 기초에 대한 확고한 이해를 갖게 될 것이다.
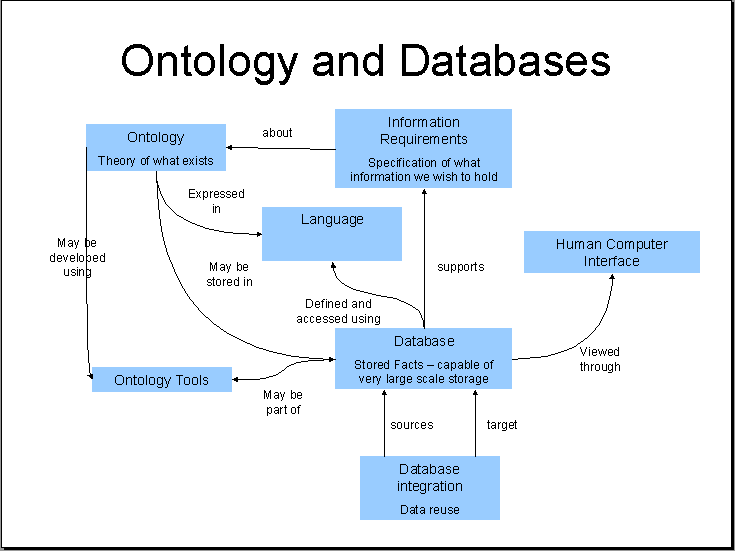
WST550 온톨로지 공학
온톨로지 공학에 대한 개괄을 목표로 한다. 온톨로지의 개념과 예, 구축에 대하여 강의하고 철학, 언어학, 인공지능, 컴퓨터공학 등에서의 논의들을 다룬다
WST560 모바일 웹과 어플리케이션
오늘날 많은 사람들이 모바일 폰을 통해서 이멜과 뉴스를 읽고 온라인 소셜 네트워크 서비스를 사용하고 있다. 스마트폰을 위시한 모바일 폰에 대한 관심은 수많은 새로운 애플리케이션을 탄생시키기도 하지만 연결, 개인 사생활 및 보안에 관련된 많은 이슈들을 만들어낸다. 본 과목에서는 스마트폰으로 대변되는 모바일 시스템과 애플리케이션에 대한 최근 동향을 살펴보기로 한다. 강의에서는 기초 이론을 다룬 후, 논문 발표와 토론을 통해 모바일 폰의 다양한 융합 학문적 문제를 살펴보기로 한다.
WST590 웹이용자의 정보행동 연구방법론
웹은 정보를 수집, 저장, 처리할 수 있는 보물창고이다. 정보추구를 보다 효율적이고 효과적으로 하기 위해서 웹서비스가 인간의 필요와 욕구를 충족시켜 줄 수 있어야 한다. 즉 웹 이용자들이 바라고 있는 정보관련 서비스는 무엇인지, 그리고 개발된 웹서비스가 웹이용자들에게 만족감을 주는지를 파악하는 것은 현재의 웹상황을 개선하는 것은 물론, 미래의 웹서비스를 선도하기 위한 필수작업이다. 이를 위해 이번 과목에서는 웹에서 나타나는 정보추구행동을 어떻게 조사할 수 있는지, 그리고 시험적 웹서비스를 어떻게 평가할 수 있는지에 관한 응용 사회과학적 관점을 학습하고 어떻게 현실에서 적용할 수 있는지 실제로 적용하며, 그 타당성을 토론할 것이다. 보다 구체적으로 융합과학의 관점에서 응용 사회과학이 어떻게 기술 개발에 아이디어를 줄 수 있으며, 해당 기술에 대한 평가가 어떻게 이루어질 수 있는지를 살펴볼 것이다.
WST591 웹 수용자 연구
웹의 등장은 기존의 미디서 시스템의 근간을 흔들고 있다. 신문, 텔레비전, 라디오 등의 수용자 중 상당수가 웹으로 옮아가고 있으며, 무엇보다 웹2.0 시대를 맞아서 수용자의 참여가 가능해 졌다. 이번과목에서는 다음의 두 가지 문제를 중심으로 웹의 등장과 뉴미디어 시대의 관련성에 대해 탐구하고자 한다. 첫째, 전문적 문화산업 종사자와 일반인 모두 미디어 콘텐츠 개발에 참여하며, 둘째, 기존 미디어와 뉴 미디어는 상호경쟁하면서도 상호공존하는 패턴을 보이고 있다. 이 교과에서는 기존 미디어의 수용자 연구를 학습하고 웹이 주도하고 있는 미디어 융합과 통합의 시대에서 기존 연구들의 한계는 무엇이고 어떻게 극복되는지를 살펴보기로 한다. 특히 이 수업에서는 뉴 미디어 시대의 수용자 조사 연구(콘텐츠 노출, 수용)는 어떻게 변해야 하며, 웹상황에서 어떠한 방식으로 데이터를 저장, 수집, 분석, 활용할 수 있는지 그리고 새로운 기법을 어떻게 제안할 수 있는지를 집중적으로 다루기로한다.
WST620 웹 소프트웨어 신뢰성
본 과목에서는 다양한 웹 소프트웨어의 신뢰성을 평가하고 개선하기 위한 최근 연구동향에 대해 살펴본다. 먼저 소프트웨어 테스팅, 정적 분석, 동적 분석 기법 등 웹 소프트웨어의 신뢰성을 분석하고 검증하기 위한 기반 기술에 대해 공부한다. 특히 비전문가(일반 사용자)가 매쉬업(Mashup), 웹 매크로(Web Macro) 등을 통하여 웹 응용 소프트웨어를 개발하는 과정에서 보다 신뢰성이 높은 소프트웨어를 만들 수 있도록 하기 위한 최근 연구에 대해 살펴본다. 그리고 웹 소프트웨어 신뢰성 평가를 위한 프로그래머 대상의 실증적 연구 방법들에 대해서도 고찰한다. 이 과목에서는 텀 프로젝트의 수행을 통해 학생들이 웹 소프트웨어의 신뢰성과 관련된 새로운 기술을 익히고 구현하며 실증적 연구를 수행하도록 한다. 선수과목-WST520
WST621 외장형 메모리 자료구조
공간할당 및 질의시간이 적절한 외부메모리(EM) 구조에 관해 논한다. B-tree 인덱스 구조 외, stabbing query (1-d intervals, 2-d orthogonal range reporting, 2-d orthogonal range count/max)를 기본적으로 다루며, 이 외 persistency, boot-strapping, fractional cascading, compression, weight-balancing, logarithmic method 등 I/O면에서 효율적인 구조 개발을 위한 기본적 테크닉을 다룬다
WST622 멀티미디어콘텐츠보호
웹이나 인터넷 등 온라인에서 유통되는 각종 멀티미디어 콘텐츠를 보호하기 위한 다양한 최신 기술들을 다룬다.
WST630 고성능 컴퓨팅
슈퍼컴퓨터 혹은 병렬컴퓨터 등 고성능 컴퓨팅 시스템에 대하여 공부하고 클러스터 기반 고성능 컴퓨팅 시스템을 구축하는 것에 관하여 강의한다.
WST640 웹 정보검색
웹 상에 존재하는 정보 중에서 특정 주제의 웹 페이지를 보다 더 정확히 찾는 방법에 대하여 공부한다. 크롤링, 자연어처리, 인공지능 등의 이슈에 대하여 다룬다.
WST650 웹 언어공학
웹의 매체인 언어를 웹사이언스에서 어떻게 다루어져야 하는지를 연구한다. 웹은 우리가 매일 쓰는 언어를 바탕으로 탄생하였고 매일 진화하고 있다. 웹을 대량의 언어 데이터인 코퍼스로서 보면, 상식 마이닝, 단어의 정의 마이닝을 할 수 있는 이론적 실험학인 계산언어학의 대량 언어데이터 가설을 적용할 수 있다. 웹은 언어의 지속적 변화를 반영하는 반사체와 같아서, 언어를 활용한 창의성을 웹컨텐츠로 분석한다. 이에는 웹 N-gram, 웹 질의 다양체론이 적용되며 특히 온라인 신문 등의 특정 도메인 적용 모델링을 탐구한다.
WST660 모바일 무선네트워크 특론
모바일 시스템의 보급과 사용의 다양성이 증가하고 있다. 이 과목에서, 특히 스마트폰과 모바일 소셜네트워크의 대두로 인하여 발생한 모바일통신체계의 기본과 실용적 진전을 공부한다. 이 체계의 핵심 – 성능, 신뢰성, 보안성, 사생활권 문제를 논의하며 이 때 최근 기술문헌, 광범위한 공동 과목과제를 활용한다.
WST665 웹 스케일 이미지 및 비디오 검색
본 교과목에서는 이미지 및 비디오 검색을 위한 관련 기술을 살펴본다. 특히 이미지/비디오 특징점 및 이의 indexing 자료구조 및 런타임 검색 알고리즘에 대하여 배운다. 또한 웹 상에 존재하는 이미지 및 비디오의 실시간 검색을 위한 확장성 검색 알고리즘으로 집중 탐구한다.
WST670 온라인 소셜네트워크
플랫폼으로써의 온라인 소셜 네트워크의 성장은 단순히 전산학적 측면에서의 연구 뿐만 아니라 인지과학, 사회학, 정치학, 언론학 등 다양한 분야와의 융합 연구의 필요성도 크게 대두되고 있다. 본 과목에서는 온라인 소셜 네트워크의 특성과 네트워크적 특성을 이용한 융합 분야 활용을 위한 기초 이론과 데이터 분석을 다룬다.
WST690 인간행위 데이터분석론
사용자 행위분석을 위한 대용량 데이터분석을 한다. 따라서 검색과 웹정보 찾기 방식을 발견 및 활용법, 인터랙션 영향 행위와 더불어, 통제실험법을 사용자 연구와 여러 기술과 함께 조합하여 배운다. 그 결과 멀티미디어, 특히 소셜미디어 환경에서 인간 행위를 볼 수 있는 통찰력을 갖게 된다.
WST891 웹사이언스공학특강
웹사이언스공학 전반에 걸쳐서 석·박사과정 현 과목 이외의 내용이 필요할 때 특강을 개설할 수 있도록 융통성 있게 운영한다..
CS500 알고리즘 설계와 해석
Algorithm Design에서의 기본적 기법인 divide-and-conquer, greedy method, dynamic programming 등을 소개 여러 컴퓨터 응용 분야에서의 사례 연구를 통하여 이러한 기법들을 익히고 또한 각 알고리즘의 time 및 spacecomplexity를 분석한다.
CS510 컴퓨터 구조
컴퓨터의 비용과 성능에 입각한 계량적인 컴퓨터 설계 원리를 소개하고, 인스트럭션세트와 인서트럭션 수행 파이프라인의 설계를 다루며, 인스트럭션의 병렬 수행 체제로서 수퍼 스칼라와 VLIW등의 인스트럭션 수준의 병렬 수행에 대하여 공부한다. 기억장치에 대하여는 캐쉬와 가상 기억체계를 포함하는 계층 기억장치의 설계와 보조 기억장치에 대하여 공부한다. 끝으로 입출력 시스템과 병렬 컴퓨터와 상호 연결망에 대하여 공부한다.
CS520 프로그래밍 언어 이론
프로그래밍 언어의 문법구조와 의미구조의 이론적 배경과 실제를 익힌다. 강의 토픽으로는 다양한 파라다임의 언어(값 중심의 언어applicative language, 기계중심의 언어 imperative language, 네트워크 중심의 언어 mobile language, 논리식 중심의 언어 logic language, 물건 중심의 언어 object-oriented language, 함수중심의 언어functional language 등)에 특화된 이론과 구현기술, 그리고 프로그래밍 언어를 설계/분석하는 정형적인 도구 등을 다룬다.
CS522 형식언어 및 오토마타 이론
Context-free grammar의 두 가지 대표적인 deterministic 파싱 방식인 LR ALC LL파싱 및 그 변형들에 관하여 공부한다. 특히 LR(k)문법의 SLR(K) ALC SLR(1) cover, LL(K) cover인 PLR(k)문법, 그리고 error recovery등을 다룬다.
CS530 운영체제
배취(Batch) 처리 소프트웨어 시스템의 기본개념과 다중처리 및 시분할 처리계에 관한 것을 배우고, 국내에서 사용되고 있는 오퍼레이팅시스템 중 하나를 선정하여 그의 구성 및 기능 등을 구체적으로 공부한다. 간단한 오퍼레이팅시스템 프로그램을 짜보고 그의 기능향상을 위한 방법 등을 연구한다.
CS540 네트워크 아키텍쳐
OSI의 reference model을 아키텍쳐 입장에서 고찰하고 각 계층의 프로토콜을 상위 계층 중심으로 살펴본다. 또한 통신 프로토콜을 어떤식으로 구성하는가에 관해 살펴보며, TCP/IP, SNA, PC간 네트워크 등 여러 네트워크 아키텍쳐의 비교분석을 통해 그 장단점을 강의 및 토론한다.
CS548 고급 정보 보호
과목의 목적은 정보 보안에 대한 포괄적인 지식을 교육하는데 있다. 과목내용은 정보보안에 초점을 두어 수학, 전산 및 통신 분야의 기초적인 지식을 바탕으로 정보보안의 개념을 암호, 접근통제, 통신규약 그리고 이와 관련된 소프트웨어로 재 분류, 체계화 하여 전반적인
정보보안에 대한 이해를 제공한다.
CS550 소프트웨어 공학
신뢰도 높은 소프트웨어를 능률있게 개발하는데 요구되는 기본개념을 소개하며 life cycle 모델, 개발단계별 기법, 자동화 도구, 프로젝트 관리기술, 소프트웨어 개발환경, 신뢰도 및 자원활용모델, 소프트웨어 metrics 등을 논의한다.
CS560 데이터베이스 시스템
데이터베이스 운영시스템을 설계, 구현하는데 필요한 기본개념과 구조를 이해시킬 목적으로 데이터베이스의 개념, 데이터구조방법, 데이터 모델의 개념, 데이터 기술언어, 질의 최적화, 동시성 제어, 원자성과 신뢰성, 그리고 현 시스템들의 분석을 취급한다.
CS562 데이터베이스의 설계
데이터베이스 시스템의 효과적인 활용을 위해 필요한 데이터베이스의 기본적인 이론 및 응용에 관하여 공부한다. 데이터모델, 데이터베이스 표준언어, 논리적 설계와 물리적 설계, 데이터베이스의 성능향상 기법, 데이터베이스 시스템의 기본적인 구현 기술등에 관하여 논의한다.
CS570 인공지능
인공지능의 중요한 개념 및 기본적인 기법과 응용시스템에 관하여 공부한다. 지식표현방법, 경험적 탐색, 문제해결, 놀리 및 추론, 학습 등을 다룬다. 자연언어처리, 패턴인식, 컴퓨터시각, 음성인식, 신경망 등에 대하여 개략적으로 고찰한다.
CS574 자연언어처리I
자연언어는 인간과 컴퓨터/로봇 상호작용을 위한 자연스러운 의사소통도구로, 그리고 각종문서의 내용기술도구로 필수적으로 사용된다. 이러한 자연언어 표현의 이해 및 생성을 위하여 단어, 구문, 의미 및 화행에 대한 단계별 연구 결과들을 검토하고 정보 추출, 질의 응답, 대화 에이전트, 기계번역 등의 응용 분야에 대해서 논의한다.
CS580 컴퓨터 그래픽스
대화형 3차원 컴퓨터 그래픽스를 이론적으로 고찰하고 실습을 통하여 익힌다. 컴퓨터 그래픽스 기본 모델과 그래픽 하드웨어와 소프트웨어를 포함한 그 구성요소 및 이들의 역할과 상호관계를 정립하고 3차원 물체의 모델링 및 렌더링 기법을 다룬다.
CS600 그래프 이론
트리, 최소경로, 연결도, 오일러그래프, 해밀톤그래프, matching. Coloring, planar그래프 , network flow 등의 기초이론과 응용에 대해서 강의한다.
CS664 고급 데이터베이스 시스템
데이터베이스 시스템의 formal foundation에 대하여 공부한다. Deductive database, relational database theory, fixed point theory, stratified negation, closed world assumption, safety, multi valued dependency, generalized dependency 등과 파손 복구를 포함한 advanced topic들에 대하여 깊이 있게 공부한다. 데이터베이스 시스템 또는 그에 대등한 과목을 먼저 수강함을 원칙으로 한다.